El problema que justifica el sistema
San Nicolás tiene 170.000 habitantes. Antes de Santia, hacer un trámite municipal implicaba ir en persona: tomar número, esperar, volver si faltaba un papel. Los vecinos llegaban a ventanilla para preguntar el horario de atención. El volumen de consultas simples que ocupaban tiempo de operadores era enorme.
El objetivo no era sofisticado: mover el 80% de las consultas cotidianas a un canal que los vecinos ya tienen instalado y saben usar. WhatsApp tiene penetración de 95%+ en el grupo demográfico que más usa los servicios municipales. No había que convencer a nadie de descargarse una app.
Pero 'un bot de WhatsApp' puede significar muchas cosas. La diferencia entre un bot de menú con botones numerados y un asistente real que entiende texto libre es abismal en términos de adopción. Esa tensión, entre predictibilidad de los flujos y flexibilidad del lenguaje natural, es el tema central de toda la arquitectura.
La arquitectura en una imagen
Hay seis piezas fundamentales: el canal (WhatsApp vía Gupshup como BSP), el orquestador (BuilderBot), los flujos determinísticos para intents conocidos, el agente IA (n8n + LLM) para consultas abiertas, el panel CRM para escalamiento humano, y la capa de persistencia (PostgreSQL + AWS S3).
La decisión de arquitectura central es que BuilderBot actúa como router: clasifica el intent de cada mensaje y decide si lo maneja un flujo fijo, el agente IA, o lo deriva a un operador. Esa separación permite iterar cada capa de forma independiente.
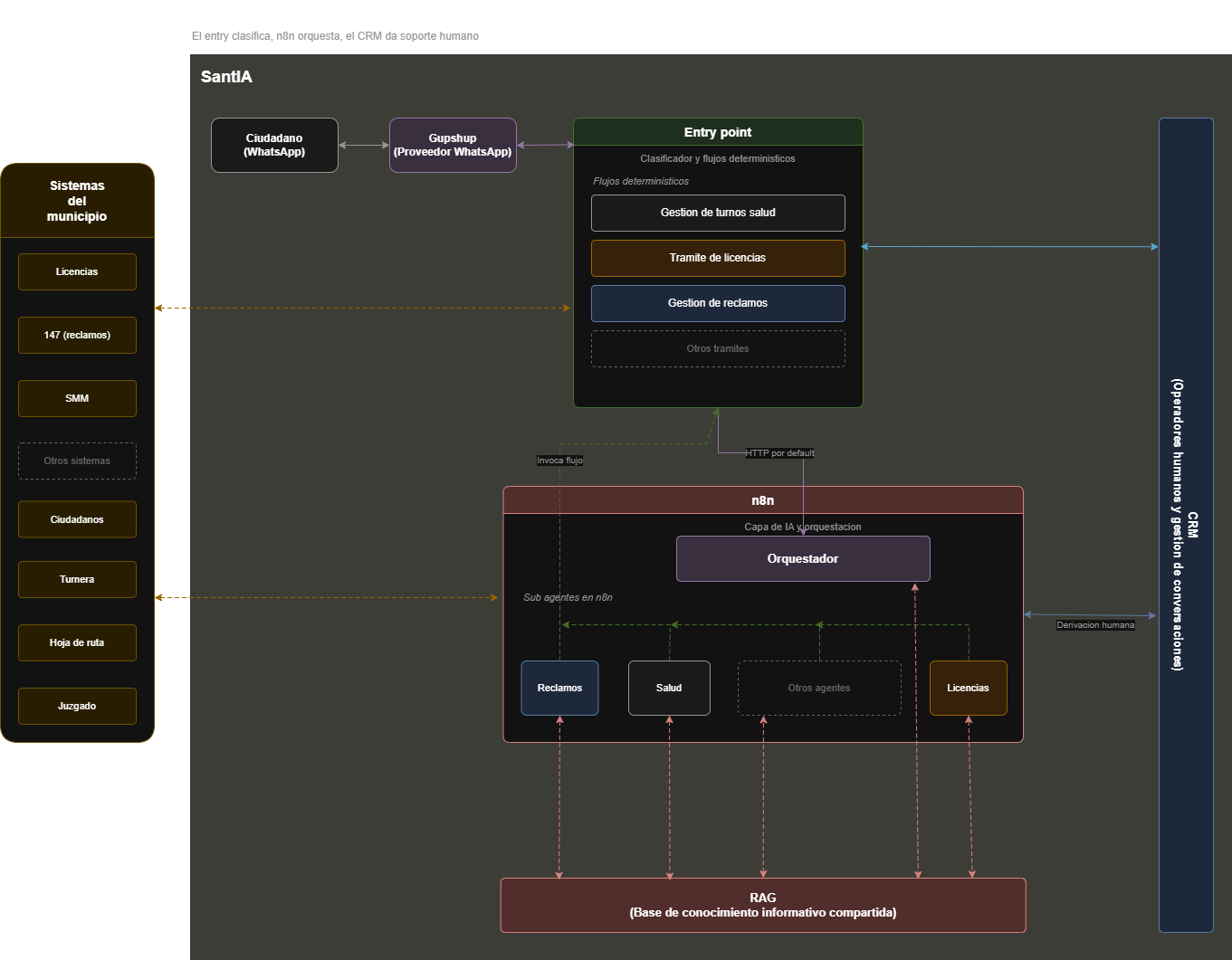
BuilderBot: el orquestador que no inventa
BuilderBot es un framework de Node.js/TypeScript pensado específicamente para flujos conversacionales sobre WhatsApp. No es un LLM wrapper ni un chatbot genérico: es un sistema de flujos con estados, condiciones y transiciones. Lo elegimos porque el modelo de programación es explícito: cada flujo es código, cada transición es testeable, y el comportamiento del bot en paths conocidos es 100% determinístico.
El patrón central es el flujo-keyword: BuilderBot escucha palabras clave o patrones en el mensaje del usuario y activa el flujo correspondiente. Dentro de cada flujo hay steps secuenciales que pueden pedir input, consultar APIs externas, guardar en base de datos y enviar respuestas. Para los trámites conocidos (turnos, boletas, infracciones, certificados) este modelo es exactamente lo que necesitamos.
El problema es la superficie de intents. Con decenas de trámites distintos, mantener un árbol de keywords exhaustivo y sin colisiones requiere disciplina. Cada trámite nuevo es un flujo nuevo, cada variante en la forma de pedirlo requiere un keyword adicional o una regex. A medida que crece el catálogo de servicios, el mantenimiento se vuelve el cuello de botella.
- Comportamiento determinístico: ideal para trámites con pasos fijos y validaciones contra APIs.
- Integración directa con Gupshup vía webhook, sin abstracción adicional.
- Persistencia de estado de conversación en PostgreSQL entre steps.
- Puppeteer para generar PDFs de boletas y certificados que se envían como archivos adjuntos.
Flujos determinísticos vs agente IA
La pregunta que aparece inevitablemente: ¿por qué no usar IA para todo? La respuesta es costo, latencia y confiabilidad. Un flujo de sacar turno médico tiene 4 pasos fijos: preguntar qué especialidad, consultar disponibilidad en la API externa, confirmar horario, guardar el turno. Ese flujo no necesita un LLM. Corre en milisegundos, no consume tokens y el resultado es predecible.
El agente IA entra cuando el ciudadano pregunta algo que no está en el catálogo: '¿cuál es el plazo para renovar el carnet de conducir si vence el mes que viene?', o 'mi vecino cortó el árbol de la vereda, ¿a quién llamo?'. Esas preguntas tienen respuesta útil pero no tienen un flujo programado. El LLM puede responder con contexto municipal sin que ningún operador tenga que intervenir.
Después de 7 meses, el split relevante es claro: 85% de las conversaciones se resuelven sin intervención humana, 15% se derivan a operadores. n8n orquesta el 100%, decidiendo en cada mensaje si ejecutar un flujo determinístico, generar una respuesta con el LLM, o escalar a una persona. El agente IA tiene el impacto desproporcionado porque resuelve exactamente los casos que antes se perdían.
| Aspecto | Flujos determinísticos | Agente IA |
|---|---|---|
| Intent | Conocido y predefinido en código | Libre, no anticipado |
| Respuesta | Fija y predecible | Generada por LLM según contexto |
| Latencia | Baja (~100-500ms) | Media (~3-10 segundos) |
| Costo por interacción | Fijo (solo infraestructura) | Por token consumido |
| Integración | APIs externas directas (síncronas) | Herramientas vía n8n |
| Mantenimiento | Alto (cada cambio es código) | Bajo (el prompt escala) |
| Uso ideal | Trámites con pasos definidos | Consultas informativas abiertas |
Gupshup y el canal WhatsApp
Gupshup es el Business Service Provider (BSP) que conecta nuestro backend con la WhatsApp Business API. Actúa como intermediario entre Meta y nuestra infraestructura: recibe los mensajes entrantes y los forwarda a nuestro webhook, y toma los mensajes salientes de nuestra API y los entrega a WhatsApp.
El punto más crítico del BSP no es técnico sino operativo: el rate limit de la API de WhatsApp. Meta impone límites por número de teléfono registrado, y superarlos significa que los mensajes dejan de llegar. Con picos de 89.000 mensajes en un solo día, el manejo del rate limiter es parte real de la arquitectura. Tenemos un servicio dedicado que cola los mensajes salientes y controla la velocidad de envío para no superar los límites.
Gupshup también maneja la verificación de números, los templates de mensajes pre-aprobados por Meta para mensajes outbound fuera de la ventana de 24 horas, y el reintento automático de mensajes fallidos. Sin esa capa, el bot sería mucho más frágil ante los cortes temporales de la API.
- Rate limiter propio (RateLimiterService) que cola mensajes salientes para no superar límites de la API.
- Templates pre-aprobados por Meta para mensajes proactivos fuera de ventana de 24h.
- Webhook de Gupshup como punto de entrada único: todos los mensajes entrantes pasan por ahí.
- Multimedia: imágenes, PDFs y audio se reciben como URLs de Gupshup y se guardan en S3.
Estado y persistencia: lo que funciona y lo que falta
El modelo de datos tiene cuatro entidades centrales: Contact (número de teléfono del ciudadano), Conversation (sesión de WhatsApp), Message (cada mensaje individual con source: BOT/WHATSAPP/CRM/OPERATOR), y ConversationDerivation (escalamiento a un operador con timestamps, departamento y estado).
Lo que funciona bien: el historial de mensajes es completo, las derivaciones tienen tiempos de respuesta trazables y el split por source permite analizar el volumen con precisión. El ratio BOT:WhatsApp es ~2:1, lo que significa que el bot envía aproximadamente dos mensajes por cada uno del usuario.
Lo que aprendimos que falta: el ciclo de vida de conversaciones no está implementado. Las conversaciones nunca se 'cierran' con un `closed_at`; todas figuran activas indefinidamente. Esto impide medir duración, tasa de abandono o resolución temporal. Y más importante: cada sesión crea un Contact nuevo con un ID diferente aunque sea el mismo número de teléfono. La recurrencia de usuarios es invisible.
- Implementar cierre automático de conversaciones por inactividad (24h sin mensajes → CLOSED).
- Normalizar contactos por número de teléfono: reutilizar el registro existente en conversaciones futuras.
- Ambas mejoras son prerequisito para métricas de retención y análisis de lifecycle.
El agente IA
El agente IA es el componente que maneja todo lo que cae fuera del catálogo de flujos determinísticos. La arquitectura: n8n recibe el mensaje cuando BuilderBot determina que no hay un intent coincidente, invoca OpenAI con contexto municipal (normativa, servicios disponibles, horarios) y devuelve la respuesta al flujo principal para mandarla por WhatsApp.
La tabla de persistencia es `n8n_chat_histories`, que guarda el historial de cada sesión con su `session_id` (derivado del número de teléfono). Esto permite que conversaciones que vuelven al agente mantengan contexto de turnos anteriores.
La mayoría de las sesiones del agente IA se resuelven sin escalar a un operador humano. Esa tasa mejorará a medida que el contexto municipal del prompt se amplíe con información de cada departamento.
Lo que aprendimos de 7 meses
La adopción real de un bot ciudadano no depende de la tecnología: depende de que el bot sea útil para los trámites que los vecinos hacen con más frecuencia. Los primeros meses demostraron que el catálogo de servicios importa más que la calidad técnica del sistema.
El patrón semanal (picos domingo-lunes, valle viernes-sábado) no era evidente antes de tener datos reales. Ese patrón informa decisiones de escalamiento: no tiene sentido tener la misma capacidad de operadores todos los días.
- El 85% de las consultas tienen un intent predecible y se resuelven con flujos: no hace falta IA para la mayoría.
- El agente IA tiene ROI desproporcionado porque resuelve los casos que antes se perdían o frustraban al ciudadano.
- Los errores sin categorizar (tipo 'SYSTEM') son deuda técnica crítica: el 74% de los errores no tienen contexto de diagnóstico.
- La recurrencia invisible es el problema de datos más urgente: sin saber si el mismo ciudadano vuelve, no hay análisis de retención posible.
- Juzgado y Corralón concentran el 55% de los escalamientos a humano: candidatos directos para flujos IA especializados.