The problem that justifies the system
San Nicolás has 170,000 residents. Before Santia, handling a municipal procedure meant going in person: take a number, wait, come back if something was missing. Residents would come to the front desk just to ask about opening hours. The volume of simple queries occupying operator time was enormous.
The goal wasn't sophisticated: move 80% of routine queries to a channel residents already have installed and know how to use. WhatsApp has 95%+ penetration in the demographic that uses municipal services most. Nobody needed to be convinced to download a new app.
But 'a WhatsApp bot' can mean many things. The difference between a numbered-button menu bot and a real assistant that understands free text is enormous in terms of adoption. That tension, between the predictability of flows and the flexibility of natural language, is the central theme of the entire architecture.
The architecture in one diagram
There are six fundamental pieces: the channel (WhatsApp via Gupshup as BSP), the orchestrator (BuilderBot), deterministic flows for known intents, the AI agent (n8n + LLM) for open queries, a CRM panel for human escalation, and the persistence layer (PostgreSQL + AWS S3).
The central architectural decision is that BuilderBot acts as a router: it classifies the intent of each message and decides whether a fixed flow handles it, the AI agent, or a human operator. That separation allows each layer to iterate independently.
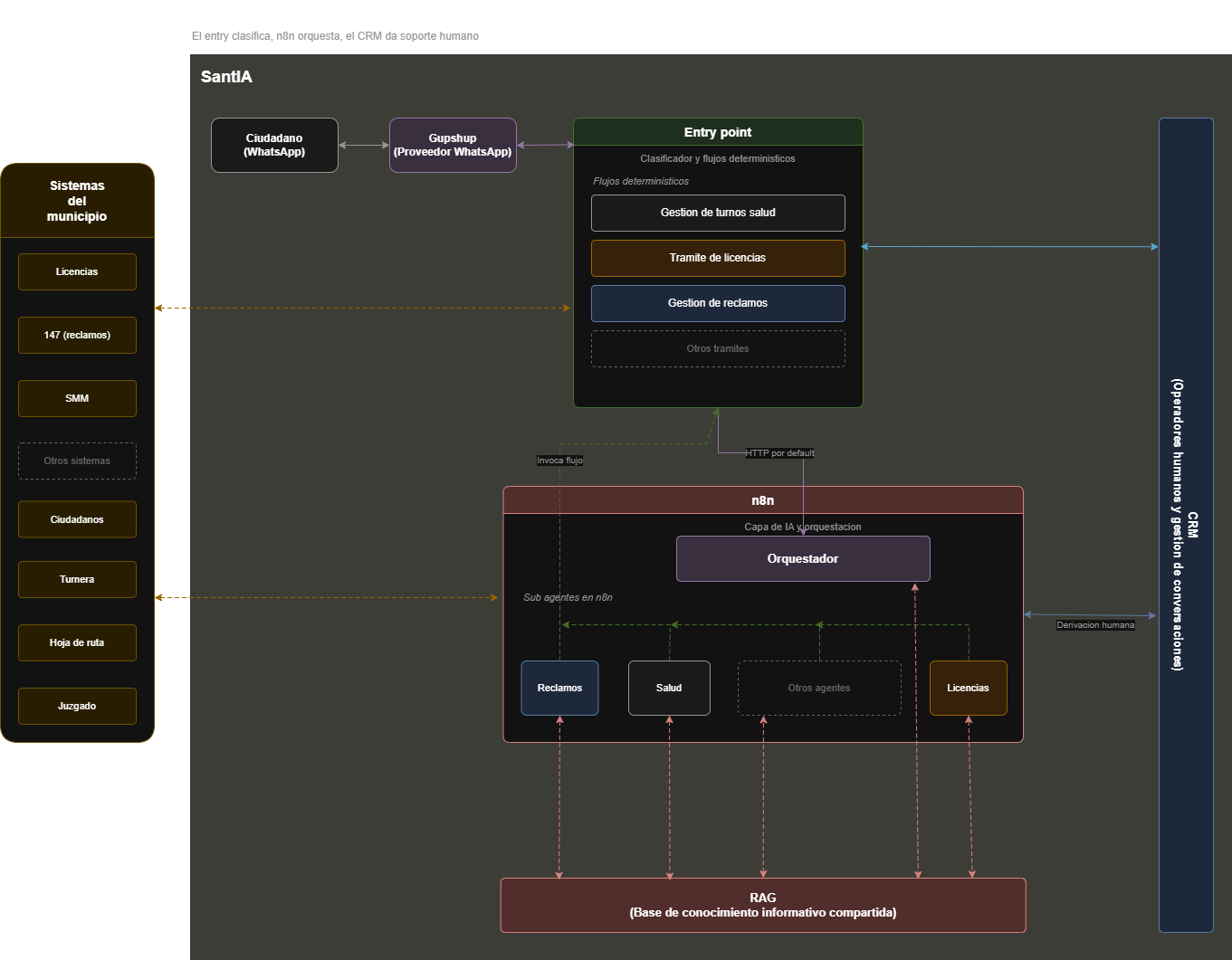
BuilderBot: the orchestrator that doesn't improvise
BuilderBot is a Node.js/TypeScript framework designed specifically for conversational flows over WhatsApp. It's not an LLM wrapper or a generic chatbot: it's a flow system with states, conditions, and transitions. We chose it because the programming model is explicit: each flow is code, each transition is testable, and bot behavior on known paths is 100% deterministic.
The core pattern is the flow-keyword: BuilderBot listens for keywords or patterns in the user's message and activates the corresponding flow. Inside each flow there are sequential steps that can request input, query external APIs, save to the database, and send responses. For known procedures (appointments, bills, fines, certificates) this model is exactly what's needed.
The problem is intent surface area. With dozens of different procedures, maintaining an exhaustive keyword tree without collisions requires discipline. Each new procedure is a new flow, each variation in how to request it requires an additional keyword or regex. As the service catalog grows, maintenance becomes the bottleneck.
- Deterministic behavior: ideal for procedures with fixed steps and API validations.
- Direct integration with Gupshup via webhook, no extra abstraction.
- Conversation state persisted in PostgreSQL between steps.
- Puppeteer generates PDF bills and certificates sent as file attachments.
Deterministic flows vs AI agent
The question that inevitably comes up: why not use AI for everything? The answer is cost, latency, and reliability. A medical appointment booking flow has 4 fixed steps: ask for specialty, check availability in the external API, confirm the slot, save the booking. That flow doesn't need an LLM. It runs in milliseconds, consumes no tokens, and the result is predictable.
The AI agent kicks in when the citizen asks something not in the catalog: 'what's the deadline to renew my driver's license if it expires next month?', or 'my neighbor cut the sidewalk tree, who do I call?' Those questions have useful answers but no programmed flow. The LLM can answer with municipal context without any operator having to intervene.
After 7 months, the relevant split is clear: 85% of conversations are resolved without human involvement, 15% are escalated to operators. n8n orchestrates 100%, deciding on each message whether to run a deterministic flow, generate an LLM response, or escalate to a person. The AI agent has disproportionate impact because it resolves exactly the cases that were previously dropped.
| Aspect | Deterministic flows | AI agent |
|---|---|---|
| Intent | Known and predefined in code | Open, unanticipated |
| Response | Fixed and predictable | LLM-generated based on context |
| Latency | Low (~100-500ms) | Medium (~3-10 seconds) |
| Cost per interaction | Fixed (infrastructure only) | Per token consumed |
| Integration | Direct external APIs (synchronous) | Tools via n8n |
| Maintenance | High (each change is code) | Low (the prompt scales) |
| Best use | Procedures with defined steps | Open informational queries |
Gupshup and the WhatsApp channel
Gupshup is the Business Service Provider (BSP) that connects our backend with the WhatsApp Business API. It acts as an intermediary between Meta and our infrastructure: it receives incoming messages and forwards them to our webhook, and takes outgoing messages from our API and delivers them to WhatsApp.
The most critical point of the BSP is not technical but operational: the WhatsApp API rate limit. Meta enforces limits per registered phone number, and exceeding them means messages stop arriving. With peaks of 89,000 messages in a single day, rate limiter management is a real part of the architecture. We have a dedicated service that queues outgoing messages and controls sending speed to stay within limits.
Gupshup also handles number verification, Meta pre-approved message templates for outbound messages outside the 24-hour window, and automatic retry of failed messages. Without that layer, the bot would be much more fragile against temporary API outages.
- Custom rate limiter (RateLimiterService) that queues outgoing messages to stay within API limits.
- Meta pre-approved templates for proactive messages outside the 24h window.
- Gupshup webhook as the single entry point: all incoming messages pass through it.
- Multimedia: images, PDFs, and audio arrive as Gupshup URLs and are saved to S3.
State and persistence: what works and what's missing
The data model has four central entities: Contact (citizen's phone number), Conversation (WhatsApp session), Message (each individual message with source: BOT/WHATSAPP/CRM/OPERATOR), and ConversationDerivation (escalation to an operator with timestamps, department, and status).
What works well: the message history is complete, derivations have traceable response times, and the split by source allows precise volume analysis. The BOT:WhatsApp ratio is ~2:1, meaning the bot sends approximately two messages for each one from the user.
What we learned is missing: the conversation lifecycle isn't implemented. Conversations are never 'closed' with a `closed_at`; all remain active indefinitely. This makes it impossible to measure duration, abandonment rate, or temporal resolution. And more importantly: each session creates a new Contact with a different ID even if it's the same phone number. User recurrence is invisible.
- Implement automatic conversation closure on inactivity (24h without messages → CLOSED).
- Normalize contacts by phone number: reuse the existing record in future conversations.
- Both fixes are prerequisites for retention metrics and lifecycle analysis.
The AI agent
The AI agent handles everything that falls outside the catalog of deterministic flows. The architecture: n8n receives the message when BuilderBot determines there's no matching intent, invokes OpenAI with municipal context (regulations, available services, hours), and returns the response to the main flow to send via WhatsApp.
The persistence table is `n8n_chat_histories`, which stores each session's history with its `session_id` (derived from the phone number). This allows conversations that return to the agent to maintain context from previous turns.
Most AI agent sessions are resolved without escalating to a human operator. That rate will improve as the municipal context in the prompt is expanded with department-specific information.
What we learned from 7 months
Real adoption of a citizen bot doesn't depend on the technology: it depends on the bot being useful for the procedures residents do most frequently. The first months showed that the service catalog matters more than the system's technical quality.
The weekly pattern (Sunday-Monday peaks, Friday-Saturday valleys) wasn't obvious before having real data. That pattern informs scaling decisions: there's no point having the same operator capacity every day.
- 85% of queries have a predictable intent and are resolved with flows: AI isn't needed for most of them.
- The AI agent has disproportionate ROI because it resolves the cases that were previously dropped or frustrated citizens.
- Uncategorized errors (type 'SYSTEM') are critical technical debt: 74% of errors have no diagnostic context.
- Invisible recurrence is the most urgent data problem: without knowing if the same citizen returns, retention analysis is impossible.
- The top two departments by escalation volume are direct candidates for specialized AI flows.